
Meta革新分布式RoCEv2网络架构:无缝串联数万GPU,赋能千亿参数量级AI模型训练
近日消息,Meta公司最近公布了一篇博客文章,揭示了他们为应对大规模分布式人工智能训练的网络需求所采取的创新举措。具体而言,该公司构建了一套基于RoCEv2协议的高性能AI网络基础设施。

这一选择旨在优化数据传输效率与降低延迟,RoCEv2(Remote Direct Memory Access over Converged Ethernet version 2)协议利用以太网技术实现远程直接内存访问,大大提升了AI模型训练场景中的网络吞吐量,是Meta面对AI时代基础设施挑战的重要布局。
RoCEv2 的全称是 RDMA Over Converged Ethernet version 2,是一种节点间通信传输方式,用于大部分人工智能容量。
Meta 公司已成功扩展了 RoCE 网络,从原型发展到部署了众多集群,每个集群可容纳数千个 GPU。
这些 RoCE 集群支持广泛的生产型分布式 GPU 训练工作,包括排名、内容推荐、内容理解、自然语言处理和 GenAI 模型训练等工作负载。
Meta 公司为分布式 AI 训练专门建立了一个专用的后端网络,能够独立于数据中心网络的其他部分进行发展、运行和扩展。
训练集群依赖于两个独立的网络:前端(FE)网络用于数据摄取、检查点和日志记录等任务,后端(BE)网络用于训练。
训练机架连接到数据中心网络的 FE 和 BE。FE 的网络层次包括机架交换机 (RSW)、结构交换机(FSW)等,其中包含存储仓库,为 GPU 提供训练工作负载所需的输入数据。
后端结构是一个专门的结构,它以无阻塞的架构连接所有 RDMA 网卡,无论它们的物理位置如何,在集群中的任意两个 GPU 之间提供高带宽、低延迟和无损传输。
为了应对 LLM 模型训练对 GPU 规模的需求,Meta 设计了聚合训练交换机(ATSW)层,将多个 AI 区域互连起来。此外,Meta 还优化路由、拥塞控制等方面,以提升网络性能。
Meta推出Motivo AI模型:让元宇宙体验更加逼真震撼
近日消息,Meta公司重磅宣布:推出Meta Motivo人工智能模型,旨在精细操控类人数字智能体的动作,全力打造沉浸式元宇宙新体验!
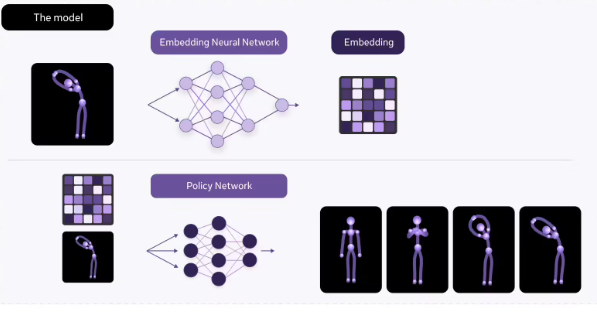
Meta 还发布了大型概念模型 LCM 和视频水印工具 Video Seal 等 AI 工具,并重申其对 AI、AR 和元宇宙技术持续投入的决心。
注:Meta Motivo 是一个基于行为的基础模型,在 Mujoco 模拟器中进行训练,使用了 AMASS 动作捕捉数据集的子集和 3000 万个在线交互样本,通过一种新型的无监督强化学习算法进行预训练,以控制复杂虚拟人形智能体的运动。
Meta Motivo 使用一种新颖的 FB-CPR 算法进行训练,该算法利用未标记的动作数据集,保留零样本推理能力的同时,将无监督强化学习引导至学习类似人类的行为。
尽管模型没有经过任何特定任务的显式训练,但在预训练过程中,动作轨迹跟踪(例如侧手翻)、姿势到达(例如阿拉贝斯克舞姿)和奖励优化(例如跑步)等任务的性能都得到了提升,展现出更接近人类的行为。
该算法的关键技术创新在于学习表示(representation),该表示可以将状态、动作和奖励嵌入到相同的潜在空间中。因此,Meta Motivo 能够解决各种全身控制任务,包括运动跟踪、目标姿态到达和奖励优化,而无需任何额外的训练或规划。
Meta“AI读心术”准确率可达80%,不开颅、不植入
Meta首席执行官扎克伯格透露,公司正在研发一种脑机技术,未来用户可以直接通过大脑输入文字。根据麻省理工技术评论报道,Meta已经成功开发出这一系统。该系统利用AI模型和特定硬件将用户的大脑信号转换成键盘字符,准确率约为80%。

这项技术的一大特点是完全依靠外部设备读取大脑信号,不需要进行植入或其他侵入性操作。尽管如此,目前的设备体积庞大且价格昂贵,单台设备估价约200万美元,并需要在隔离环境中才能发挥最佳效果。ForestNeurotech创始人萨姆纳·诺曼形容其为“一台侧放并悬挂在用户头顶的MRI机”,并不适合日常佩戴。







